Preparatevi a un viaggio nel futuro dell'intelligenza artificiale! Proprio quando pensavo di aver capito come funzionano i modelli linguistici, ecco che Meta decide di sconvolgere tutto con Llama 4. È come se avessi appena imparato a guidare una bicicletta e improvvisamente mi ritrovassi al volante di una navicella spaziale!
Meta ha presentato non uno, non due, ma ben tre nuovi modelli che fanno sembrare il mio progetto Streamlit come un giocattolo dell'età della pietra:
Llama 4 Scout: il 'piccolo' della famiglia con soli 17 miliardi di parametri attivi. Può gestire un contesto di 10 milioni di token, il che significa che potrebbe probabilmente leggere e comprendere l'intera storia della mia vita... inclusi i momenti imbarazzanti che vorrei dimenticare!
Llama 4 Maverick: il modello multimodale per eccellenza, con 400 miliardi di parametri totali. Può capire immagini così bene che probabilmente riuscirebbe a decifrare i miei scarabocchi meglio di me stesso.
Llama 4 Behemoth: con quasi 2 trilioni di parametri, questo mostro fa sembrare i miei tentativi di machine learning come se stessi cercando di costruire un razzo con i mattoncini Lego.
E io che pensavo di essere all'avanguardia con il mio progetto di chunking e RAG! Sembra che l'unica cosa che mi resta da 'chunkare' sia la mia autostima come sviluppatore AI...
Nonostante le incredibili capacità di questi nuovi modelli, c'è ancora spazio per soluzioni pratiche e accessibili come quella che ho sviluppato: un'applicazione Streamlit che integra Document Q&A e Meal Planner intelligentebasata su RAG per risolvere problemi reali.
Introduzione
Nell'era dell'intelligenza artificiale generativa, uno dei problemi più significativi rimane la capacità dei modelli di fornire risposte accurate, aggiornate e verificabili. I Large Language Models (LLM) come GPT-4 possiedono una conoscenza impressionante ma statica, limitata al periodo del loro addestramento e priva di fonti citabili. È qui che entra in gioco la Retrieval-Augmented Generation (RAG), un paradigma che sta trasformando radicalmente il modo in cui interagiamo con l'IA.
Durante il mio percorso formativo nel bootcamp AI Engineer di Edgemony, ho avuto la fortuna di approfondire questo argomento attraverso le fantastiche lezioni tenute da Ilyas Chaoua. Quello che inizialmente sembrava solo un'interessante tecnica si è rapidamente trasformato in una passione, portandomi a esplorare come questa tecnologia possa risolvere problemi reali e quotidiani.
Sono entusiasta di presentarvi il mio ultimo progetto: un'applicazione Streamlit che sfrutta la potenza del RAG per creare due strumenti pratici e innovativi: un Document Q&A e un Meal Planner intelligente. Ma prima di entrare nei dettagli dell'applicazione, facciamo un passo indietro per comprendere cosa sia realmente il RAG e perché rappresenti una svolta così importante.
Cos'è il RAG e perché è rivoluzionario?
La Retrieval-Augmented Generation è un approccio che combina la potenza generativa dei modelli linguistici con la precisione del recupero di informazioni da fonti esterne. In parole semplici, invece di affidarsi esclusivamente alla conoscenza "memorizzata" durante l'addestramento, un sistema RAG cerca attivamente informazioni rilevanti in un database o in documenti esterni prima di generare una risposta.
Come ho appreso durante il mio percorso di studi, i modelli linguistici di grandi dimensioni presentano intrinsecamente un'imprevedibilità nelle loro risposte. La loro conoscenza statica comporta un limite temporale e impedisce loro di rimanere aggiornati, portando spesso a generare risposte false o fuorvianti quando mancano informazioni sufficienti.
Le tre componenti fondamentali del RAG:
1. Retrieval (Recupero): Il sistema cerca e recupera informazioni pertinenti da una base di conoscenza o documenti specifici.
2. Augmentation (Arricchimento): Il modello linguistico viene arricchito con le conoscenze specifiche recuperate.
3. Generation (Generazione): Una risposta coerente e contestuale viene generata basandosi sia sulla conoscenza generale del modello che sulle informazioni recuperate.
Perché il RAG è importante?
Il RAG risolve alcuni dei problemi più critici dei modelli linguistici tradizionali:
Riduce le "allucinazioni": I LLM tendono talvolta a inventare informazioni che sembrano plausibili ma sono false. Il RAG minimizza questo rischio ancorando le risposte a fonti concrete.
Garantisce informazioni aggiornate: A differenza dei modelli pre-addestrati, un sistema RAG può accedere a informazioni recenti o specifiche.
Offre trasparenza e verificabilità: Le risposte possono essere accompagnate dalle fonti da cui sono state estratte le informazioni.
Personalizzazione senza fine-tuning: Permette di personalizzare le risposte in base a dati specifici senza dover riaddrestrare l'intero modello (operazione costosa e complessa).
Rispetto della privacy: I dati sensibili possono rimanere nel database dell'utente senza dover essere condivisi per addestrare un modello.
Maggiore controllo per gli sviluppatori: Come ho sperimentato direttamente, RAG offre un controllo granulare sulle informazioni disponibili all'LLM, permettendo di aggiornare, sostituire o limitare le fonti in base alle esigenze.
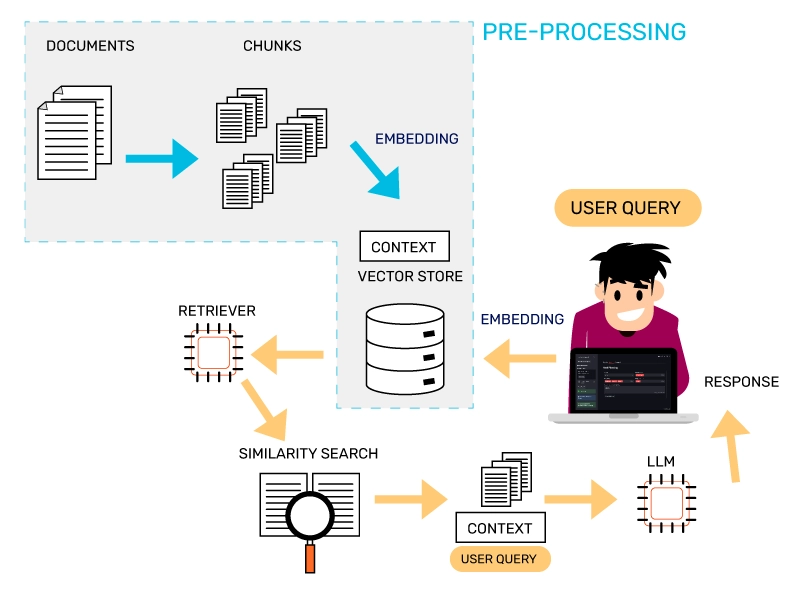
Il RAG in pratica: come funziona nella mia applicazione
Nel mio sistema, il processo RAG si svolge in quattro fasi principali:
1. Indicizzazione e Chunking: I documenti o le ricette vengono suddivisi in "chunk" (frammenti) più piccoli e trasformati in embedding vettoriali, essenzialmente "mappe semantiche" che catturano il significato del testo. Durante lo sviluppo ho sperimentato diverse strategie di chunking:
Chunking a dimensione fissa con sovrapposizione
Chunking semantico che mantiene insieme concetti correlati
Chunking ricorsivo che divide progressivamente i segmenti più grandi
Chunking basato sulla struttura del documento (titoli, sezioni, ecc.)
2. Query: Quando l'utente pone una domanda, questa viene anch'essa trasformata in un embedding vettoriale utilizzando lo stesso modello di embedding (OpenAI Embeddings).
3. Retrieval: Il sistema cerca gli embedding più simili alla query nel database vettoriale (Chroma DB). L'identificazione avviene principalmente attraverso la similarità coseno, seguita da una fase di "reranking" per evitare duplicati.
4. Generazione: I chunk recuperati vengono forniti come contesto al modello linguistico (OpenAI GPT), che genera una risposta informata esclusivamente basata su queste informazioni.
Questo approccio garantisce che le risposte siano strettamente pertinenti ai dati dell'utente e non derivino dalla conoscenza generale (e potenzialmente obsoleta) del modello.
Le due anime del mio progetto
Document Q&A: il tuo assistente documentale personale
La funzionalità Document Q&A trasforma qualsiasi documento in un assistente interattivo:
Supporto multi-formato: Carica documenti PDF, DOCX o TXT e inizia a fare domande sul loro contenuto.
Chunking intelligente: I documenti vengono suddivisi con una sovrapposizione ottimale per mantenere il contesto tra i frammenti.
Risposte precise e citabili: Ogni risposta è generata utilizzando specificamente il contenuto del documento, con la possibilità di vedere esattamente da quali parti proviene l'informazione.
Riassunti dinamici: Ottieni sintesi complete o parziali dei documenti con un semplice comando.
Questo strumento è particolarmente utile per ricercatori, studenti o professionisti che devono estrarre rapidamente informazioni da documenti complessi o voluminosi.
Meal Planner: il tuo nutrizionista digitale
Il Meal Planner intelligente porta il RAG nel mondo della nutrizione e della cucina:
Gestione ricette personalizzata: Carica e gestisci le tue ricette preferite in formato JSON.
Pianificazione pasti su misura: Genera piani alimentari personalizzati in base a durata, numero di pasti, preferenze dietetiche e allergie.
Liste della spesa automatiche: Crea liste della spesa ottimizzate e organizzate per categoria.
Questo modulo è pensato per chiunque voglia semplificare la pianificazione dei pasti mantenendo una dieta equilibrata e in linea con le proprie esigenze.
Tecnologie e architettura
Per realizzare questo progetto, ho integrato diverse tecnologie all'avanguardia:
Streamlit: Per creare un'interfaccia utente intuitiva e reattiva.
LangChain: Un framework potente per costruire applicazioni basate su LLM con funzionalità avanzate.
OpenAI API: OpenAI API - Per i modelli GPT e per la creazione di embedding vettoriali
Chroma DB: Un database vettoriale efficiente per l'archiviazione e il recupero rapido degli embedding.
PyPDF, Docx2txt - Per l'elaborazione dei documenti
RecursiveCharacterTextSplitter: Per un chunking intelligente dei documenti che preserva il contesto semantico.
L'architettura modulare dell'applicazione permette di estendere facilmente le funzionalità e di adattarla a diverse esigenze e casi d'uso.
Oltre il progetto: il futuro del RAG e gli agenti AI
Il RAG rappresenta solo l'inizio di una nuova era nell'IA, dove i modelli linguistici non saranno più sistemi isolati ma potranno interagire dinamicamente con informazioni esterne. Le applicazioni future sono praticamente illimitate:
Assistenti aziendali che possono accedere a documenti interni, knowledge base e database proprietari.
Tutor educativi personalizzati che si adattano ai materiali di studio specifici.
Sistemi di supporto clinico che integrano le più recenti ricerche mediche con le cartelle cliniche dei pazienti.
Agenti di customer service capaci di consultare in tempo reale cataloghi prodotti e politiche aziendali (già implementato da Klarna che ha eliminato Salesforce proprio grazie a questa tecnologia).
Un aspetto che mi entusiasma particolarmente è l'evoluzione verso gli agenti AI con architettura di memoria. Non vedo l'ora di sperimentare con la creazione di agenti che integrino diversi tipi di memoria:
Working Memory: Memoria a breve termine per l'elaborazione immediata
Semantic Memory: Archiviazione di fatti e conoscenze generali
Episodic Memory: Registro di esperienze e interazioni passate
Procedural Memory: Informazioni su come eseguire azioni specifiche
Questa architettura permetterà di creare agenti AI che mantengono coerenza durante conversazioni prolungate, ricordano interazioni precedenti, apprendono da esperienze passate e migliorano nel tempo - tutte funzionalità che mi piacerebbe implementare nelle future iterazioni del mio progetto.
La mia esperienza formativa e prossimi passi
Questo progetto rappresenta la sintesi pratica delle conoscenze acquisite attraverso:
Il corso "Developing LLM Apps with LangChain" della scuola Zero to Mastery.
Le preziose lezioni sul RAG tenute da Ilyas Chaoua durante il bootcamp AI Engineer di Edgemony.
Durante questo percorso, ho anche imparato ad affrontare alcune delle sfide principali dei sistemi RAG, come la gestione della lunghezza del contesto, la robustezza contro informazioni controfattuali, e l'ottimizzazione degli approcci ibridi che combinano RAG con modelli fine-tuned.
L'applicazione dimostra come concetti teorici avanzati possano tradursi in soluzioni pratiche a problemi reali, sfruttando le più recenti innovazioni nel campo dell'intelligenza artificiale.
Conclusioni
Il RAG non è semplicemente un miglioramento incrementale dei sistemi di IA esistenti, ma un vero e proprio cambio di paradigma che ridefinisce come interagiamo con l'informazione attraverso l'intelligenza artificiale. Il mio progetto Streamlit rappresenta un piccolo ma significativo passo in questa direzione, dimostrando come anche applicazioni relativamente semplici possano sfruttare questa tecnologia per creare esperienze utente più ricche, accurate e personalizzate.
Guardando al futuro, sono particolarmente interessata ad esplorare le nuove frontiere del RAG:
RAG multimodale che include immagini, audio e video
RAG personalizzato che si adatta alle preferenze dell'utente
RAG riflessivo capace di valutare autonomamente la qualità delle proprie risposte
RAG collaborativo che combina conoscenze da più fonti
Soprattutto, non vedo l'ora di sperimentare con la creazione di agenti AI dotati di architetture di memoria avanzate, che potranno elevare ulteriormente le capacità del mio sistema RAG attuale.
Invito tutti gli interessati a esplorare, utilizzare e magari contribuire al progetto, disponibile sul mio GitHub e provare l'applicazione su streamlit. La rivoluzione RAG è appena iniziata, e sono entusiasta di farne parte e di continuare a spingerne i confini!
Poco fa, mentre guardavo un episodio di Grey's Anatomy, una frase mi ha colpita: "La nostra meta-analisi conferma la correlazione tra il microbioma intestinale e l'Alzheimer." "Bene, allora guardiamo i dati." Ma i dati, da soli, non raccontano tutta la storia. La correlazione ci dice che due fenomeni si muovono insieme, ma non ci dice […]
🎉 Level Up! Ho appena completato il corso “Complete Python Developer: Zero to Mastery” e mi sento come se avessi appena sbloccato un nuovo achievement nel mondo della programmazione! 🏆🐍 Un viaggio entusiasmante affrontato con il mio approccio preferito: sperimentare, costruire e imparare divertendomi… e sì, anche combattere qualche bug lungo il cammino. Ma del […]